Computer Adaptive Testing on the NCLEX: How CAT Really Works
A student-friendly explanation aligned to the April 2026 NCLEX Candidate Bulletin: how CAT chooses your next item, why question count does not predict pass or fail, and what to actually focus on test day.
Quick Answer: What CAT Means
The NCLEX is not a fixed test where every candidate answers the same questions in the same order. It is a computerized adaptive test, often called CAT. The exam estimates your ability as you answer, then chooses each next item based on your current estimate, the NCLEX test plan, and how much information that item can add to a pass/fail decision.
The most important point for students: the number of items you receive does not tell you whether you passed or failed. Short exams can be a pass or a fail. Long exams can be a pass or a fail. CAT is trying to determine whether your ability is above or below the passing standard with enough statistical confidence to stop.
This guide focuses on the mechanics — how the algorithm selects items, what theta means, and the three stop rules. For the foundational overview, see our Computer Adaptive Testing explainer. If you instead want to know what to actually do on exam day — pacing, managing anxiety, and why every question feels hard — read our NCLEX CAT test-day strategy guide.
What's Actually True Before We Go Deeper
Source-aligned facts about NCLEX CAT
- 1.Reviewed against the April 2026 NCLEX Candidate Bulletin and the 2026 NCLEX-RN and NCLEX-PN test plans published by NCSBN.
- 2.Both NCLEX-RN and NCLEX-PN are variable-length CAT exams: 85–150 items, 5 hours, 15 unscored pretest items per exam.
- 3.RN Test Pro is independent and not affiliated with or endorsed by NCSBN. NCLEX® is a registered trademark of the National Council of State Boards of Nursing, Inc.
- 4.This guide is for exam preparation. Practice readiness estimates are study guidance, not official exam outcomes or pass predictions.
2026 NCLEX CAT Facts
The single most useful thing to anchor before reading anything else about CAT: the actual exam-format numbers. Both versions of the NCLEX share the same shape under the April 2026 Candidate Bulletin.
| Feature | NCLEX-RN | NCLEX-PN |
|---|---|---|
| Format | Computerized adaptive test | Computerized adaptive test |
| Minimum items | 85 | 85 |
| Maximum items | 150 | 150 |
| Time limit | 5 hours | 5 hours |
| Pretest items | 15 (unscored) | 15 (unscored) |
| Skip and return? | No | No |
| Question count predicts outcome? | No | No |
Pretest items are unscored items used to collect data for future exams. They look like regular questions and you cannot tell which is which. Treat every item seriously.
How CAT Selects Your Next Question
CAT does not pick the next item randomly. After every submitted answer, the computer updates its estimate of your ability based on all your previous responses and item difficulties. Then it picks the next item using several priorities at once.
- Ability match — the item is close to your current ability estimate so it provides useful information.
- Test-plan coverage — the exam must cover the required Client Needs categories, not just whichever items match your level.
- Measurement value — the item should help decide whether your ability is above or below the passing standard.
- Item exposure rules — the exam manages how often specific items are delivered and avoids over-using particular items across the candidate pool.
That is why “harder if I got it right, easier if I got it wrong” is an oversimplification. Difficulty matters, but content balance and measurement value matter at the same time.
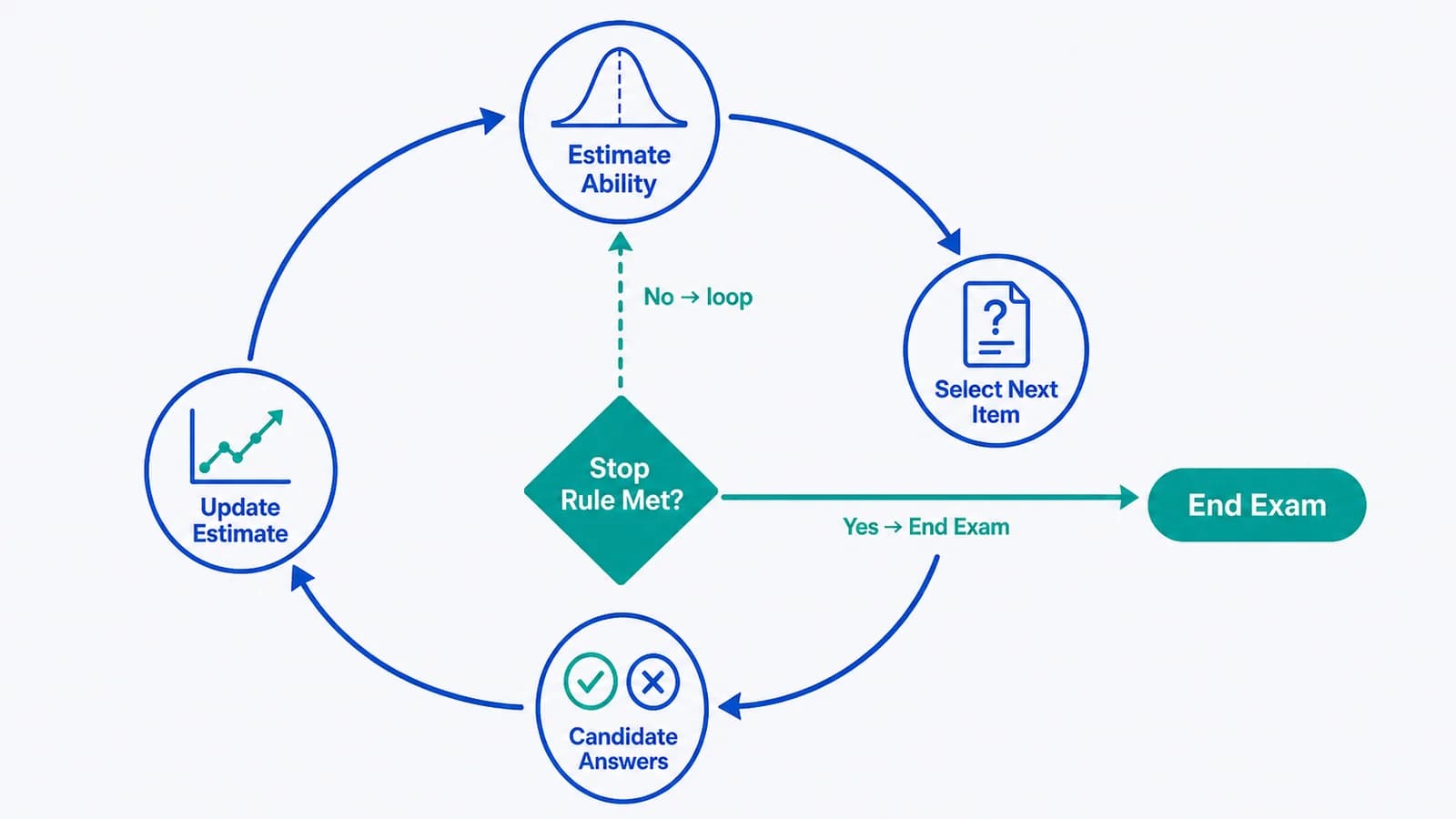
Each answer updates the ability estimate; the algorithm checks the stop rule before selecting the next item.
What Theta Means Without Overcomplicating It
Theta is a statistical estimate of ability. You will not see your theta during the NCLEX, and you do not need to compute it. The important concept is that CAT is not just counting how many items you got right. It is estimating your ability based on the difficulty and scoring of the items you answered.
Each new answer changes the estimate. Early in the exam, the estimate moves more. Later it tends to stabilize as more information is gathered. Around the estimate sits a confidence interval — a band that gets narrower as confidence in the estimate increases.
The exam compares your estimated ability with the passing standard set by NCSBN. You pass when the decision rules determine your ability meets or exceeds the standard.
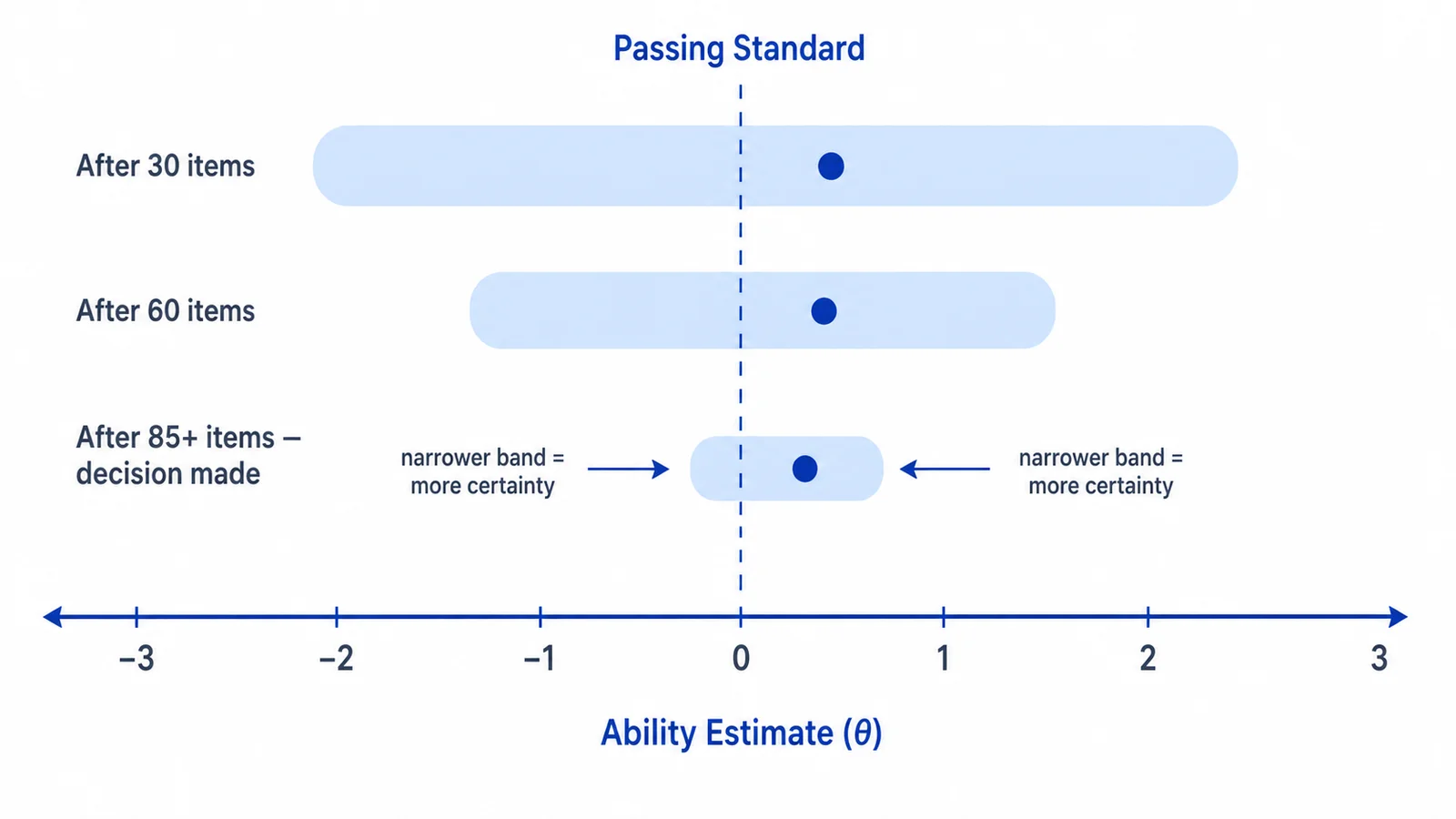
The confidence band around your ability estimate narrows as more items are answered.
The Three NCLEX Stop Rules
The NCLEX can end in three main ways. Knowing them in advance helps reduce mid-exam panic.
95% Confidence Rule (most common)
After you reach the minimum number of items, the exam can stop when it is 95% confident your ability is clearly above or clearly below the passing standard. Above the standard with confidence: pass. Below the standard with confidence: fail.
Maximum-Length Exam Rule
If your ability estimate stays close to the passing standard, the exam may continue to the maximum number of items. The final ability estimate from completed scored items determines pass or fail.
Run-Out-of-Time Rule
If time expires before the exam reaches a decision: if you didn't reach the minimum, fail. If you did reach the minimum, the exam uses your final ability estimate from completed items to decide pass or fail.
Pacing matters because of stop rule 3. You do not need to rush, but spending too long on individual items can leave you short of the minimum or with weaker estimates near the end of your 5-hour window.
Why 85 or 150 Questions Doesn't Predict Outcome
One of the most damaging NCLEX myths is that the question count predicts your result. It does not.
- You can pass at the minimum number of items.
- You can fail at the minimum number of items.
- You can pass at the maximum number of items.
- You can fail at the maximum number of items.
Question count tells you how long it took the exam to reach a decision (or that it needed the maximum amount of information available). It does not tell you which side of the passing standard you ended up on.

Any length on the 85–150 range can result in pass or fail.
A better test-day mindset: do not count items as a pass/fail signal, do not panic if the exam continues, do not celebrate or give up if it shuts off early, and treat each item as a fresh clinical-judgment task.
Hard Questions and SATA Myths
Myth: Getting harder questions means I'm passing.
Reality: Harder-feeling questions may mean the exam is challenging you near your estimated ability, but perceived difficulty is not a reliable pass/fail signal. A question can feel hard because the content is weak for you, not because the item is statistically high difficulty.
Myth: If I get 150 questions, I probably failed.
Reality: Reaching the maximum just means you were near the borderline and the algorithm needed more data. The decision is based on the final ability estimate, not the question count.
Myth: If I finish at 85, I either nailed it or completely tanked.
Reality: Both can be true. Stopping at the minimum simply means the algorithm reached statistical confidence quickly — that confidence can land on either side of the passing standard.
Myth: SATA questions are always harder than multiple-choice.
Reality: Format does not equal difficulty. Multiple-response items appear at a range of difficulty levels, and item format alone tells you nothing about how the exam is going.
Myth: I can game the algorithm by answering slowly.
Reality: CAT scores correctness (and partial credit on applicable items), not response time. Pacing matters because of the 5-hour time limit, not because the algorithm rewards slow thinking.
How NGN and Partial Credit Fit Into CAT
The Next Generation NCLEX added more clinical-judgment measurement through case studies and newer item formats. Items with more than one correct key may receive partial credit using NCSBN's scoring methods, which can include plus/minus, zero/one, and rationale scoring depending on item type.
NGN does not replace CAT. CAT still drives exam delivery; NGN changes the kinds of clinical-judgment tasks you may see inside that adaptive exam. For more on the formats themselves, see our NCLEX question types guide and the Next Generation NCLEX overview.
How to Prepare for a CAT Exam
- Practice one-question commitment. You cannot submit, advance, and return. Train yourself to read carefully, choose the safest answer, submit, and move on mentally.
- Build clinical judgment, not just recall. Many items are not asking “do you remember this fact” — they are asking “what matters most right now.” Practice recognizing the clinical task: assessment, priority, delegation, teaching, safety, evaluation.
- Use mixed practice. CAT can move across Client Needs categories, so train across pharmacology, safety, psychosocial integrity, physiological adaptation, management of care, and NGN-style case thinking.
- Learn pacing. Some items, especially case studies, take longer. Keep a steady pace and avoid getting trapped on a single item.
- Stop interpreting the exam during the exam. You cannot identify pretest items, you cannot see your theta, you cannot know whether the exam is about to stop. Your job is to answer the current item safely.
For a deeper look at study structure, see our NCLEX study plan and test day tips.
How RN Test Pro Uses Adaptive Practice
Our practice platform uses adaptive question selection built on the same psychometric principles that underlie CAT — IRT-based ability estimation and information-maximizing item selection — so you can rehearse changing difficulty, content balancing, and one-question-at-a-time testing before exam day.
That does not mean RN Test Pro is the official NCLEX or that it uses NCSBN's exact algorithm. It means our practice system is designed around the same preparation problem: answering one item at a time, handling shifting difficulty, and making safe clinical judgments under pressure. RN Test Pro is independent and not affiliated with NCSBN.
Practice CAT-Style NCLEX Questions
Start with an adaptive diagnostic to identify strengths and weak areas. Then focus your study where it matters most.
Start Free DiagnosticFrequently Asked Questions
Does 85 questions mean I passed?
No. The minimum number of items can result in either pass or fail. It only tells you the exam reached a decision after the minimum, not what that decision was.
Does 150 questions mean I failed?
No. Reaching the maximum means the exam needed more information to reach a confident decision. Your result depends on the final ability estimate, not the count.
Can I skip NCLEX questions and come back later?
No. You must answer each item before moving on. Once you confirm and move forward, you cannot return to a previous question.
Are SATA questions always harder?
No. Item format does not automatically equal difficulty. Multi-response items appear at a range of difficulty levels.
Does getting harder questions mean I'm passing?
Not by itself. Harder-feeling questions can suggest the exam is challenging you near your estimated ability, but candidates are poor judges of statistical item difficulty. Focus on the current item, not the perceived pattern.
Should I study with adaptive practice?
Adaptive practice helps you get used to changing difficulty and one-question-at-a-time testing. Combine it with content review, NGN case practice, and clinical-judgment training for a balanced prep.
Bottom Line
CAT is not a mystery once you understand the purpose: the NCLEX is estimating whether your ability is above or below the passing standard while covering the required content areas. Question count, SATA count, and perceived difficulty do not prove your result.
Your best strategy is to prepare with mixed NCLEX content, practice NGN clinical judgment, build pacing, and answer one item at a time without trying to decode the algorithm during the exam.
Related Topics
Computer Adaptive Testing →
The foundational CAT explainer — start here for the overview.
CAT Test-Day Strategy →
Pacing, managing exam anxiety, and why every question feels hard.
NCLEX Scoring Guide →
Theta, IRT, and how the passing standard works.
Next Generation NCLEX →
Case studies, partial credit, clinical judgment items.
Client Needs Categories →
How CAT balances content, not just difficulty.
Adaptive vs Static Practice →
When to use each format in your prep.